DataOps — Closing the Gap between Data and Insights More Effectively

Authored by Shashank Tikku | Practice Head – QA / DataOps @ BigTapp Analytics
The adoption of advanced analytics is relatively high, with more than 90% of com-panies recognizing its value. However, unlocking the full potential of analytics re-mains a significant challenge for most businesses. The lack of automated tools and automated testing makes companies spend around 80%1 of their time (according to a McKinsey report) on repetitive tasks around data. A further 70% or more of data integration, migration, and business intelligence initiatives fail on their first attempt as businesses create more data than ever.
DataOps responds to this challenge through an automated, process-oriented methodology focusing on improving quality and reducing the cycle of advanced analytics. A Gartner research found that organizations believe poor data quality to be responsible for an average of $15 million per year in losses.
Making a difference
Enhanced Data Quality
The increasing demand for real-time data and insights requires quality testing at every stage of its lifecycle. DataOps automation and processes make this kind of iterative testing possible and allow for efficiently scaling business data and reporting processes.
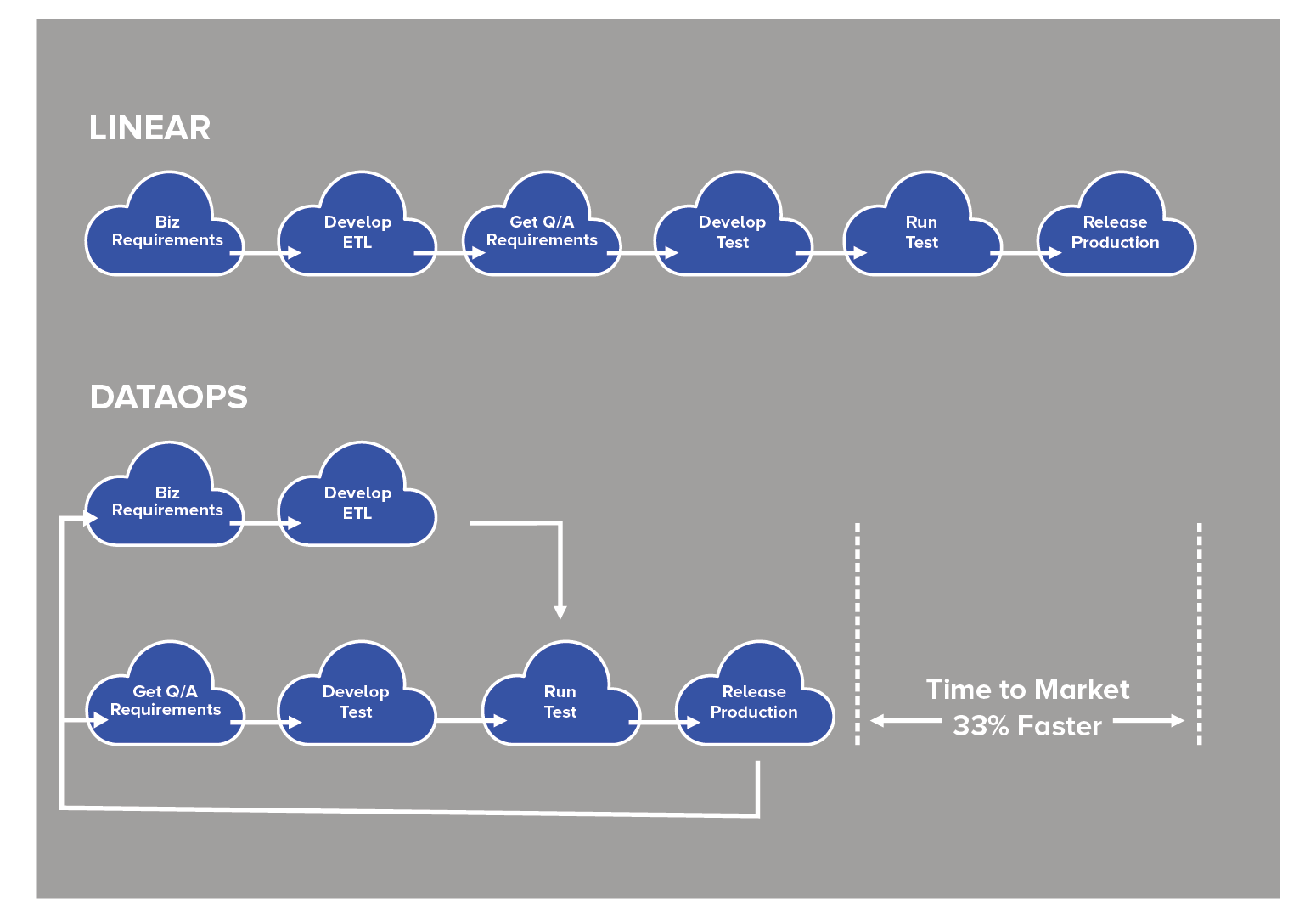
Faster roll-out of new features
DataOps is a practice that aims to automate the testing process and release new features and updates, resulting in faster and more efficient development iterations. DataOps reduces the risk associated with manual testing and inadequate tools and increases the volume of new features by 50%.
Opening up insights
By promoting partnerships among data scientists, data engineers, DevOps engineers and other technologists, DataOps allows for a more seamless, in-sync working with data in a shorter time. With DataOps in the scene and the emergence of cloud data warehouses and code-free visualization dashboards, decision-makers have direct access to the insights they need without having to depend on data teams.
Issues faced by industries
Organizations grapple with specific challenges that block achieving their analytics and data management goals. Let’s take a look.
Lack of data utilization awareness
Lack of data utilization is a common problem faced by many organizations today. The sheer amount of generated data can be overwhelming and make it difficult to manage and utilize it effectively. This can lead to data silos, where different departments or teams work with isolated data sets and a lack of overall data visibility, eventually slowing down the issue resolution process.
Unable to manage jobs
Maintaining and handling the many processes and jobs running simultaneously across different clusters and data pipelines is challenging. With a DataOps process to take measures with personalized recommendations and automation to improve and optimize the performance of all ongoing jobs, it is easier to determine issues fast with just AI and advanced analytics.
Lack of Data pipeline understanding
A data pipeline eradicates numerous manual steps and allows an automated flow from one data stage to another. By automating the processes involved in extracting, altering, integrating, validating, and loading data for analysis, efficiency and effectiveness are improved.
A DataOps team needing to completely understand how the data pipeline works can offset all the advantages it sets out to offer. For example, a data pipeline update schedule. You cannot fully benefit from the data without knowing the SLAs and types like batch and real-time, native, or open source.
The Roadmap
Managing data and analytics requires establishing a clear business goal, assembling highly qualified data engineers, and implementing the appropriate tools. Organizations must embrace a mix of meticulous controls, the appropriate technologies, and upskilling initiatives. There are a few fundamentals that need to be in place.
A culture shift: DataOps is a mindset change about breaking down walls between the various data users, be it business users or developers or testers. Bringing all teams together and working as a unit with shared responsibilities is core to DataOps.
Code Repository: A key feature of DataOps is to ensure that "code" is accessible to automation tools. All data pipeline artefacts, like database code, ETL code etc., are treated as code and stored in the Code Repository.
Continuous Integration and Deployment (CI/CD): To respond to a business's ever-present needs, a QA and production environment ready for subsequent execution is paramount. DataOps should have a repeatable, directed pipeline for data and schemas.
Automated testing: Manual testing is tedious and time-consuming for iterative or multiple changes. A DataOps automated testing approach involves test automation and includes an automatically scaling platform that enables thousands of tests to be done in minutes.
Defining the DataOps Practice: Once the user roles and responsibilities are established and the tools are in place, the next step is to define the requirements process, development process, data testing process, test data management, and production monitoring and defect tracking.
Component design: The components of data processes should be easy to understand, maintain, and test so that they can be assembled into advanced systems.
Production monitoring: Testing rules are left in place by development and testing teams so that when the system goes live, the production data pipeline can be monitored continuously.
Management, security, and modification control: It is important to document each change in a shared repository so it can be tracked, replicated (or rolled back), adequately approved, and reported during an audit.
(Note: we can recreate this if you are okay with this version)
A Typical DataOps Architecture

https://tdwi.org/articles/2019/04/30/adv-all-future-of-dataops-four-trends.aspx
https://datakitchen.io/add-dataops-tests-to-deploy-with-confidence/
https://www.dataversity.net/dataops-highlights-the-need-for-automated-etl-testing-part-1/
https://bigeval.com/dta/dataops-process-dataquality-datatesting/
https://www.sav.vc/blog/why-we-believe-dataops-is-the-next-big-thing-in-the-data-world
Shashank Tikku
Practice Head – QA / DataOps @ BigTapp Analytics
QA professional with over 14 years working in various capacities and leading test teams across different industries, primarily in the U.S. and India. Experience working in an Agile development environment employing Scrum methodology focusing on functional, automation, performance and ETL testing.

